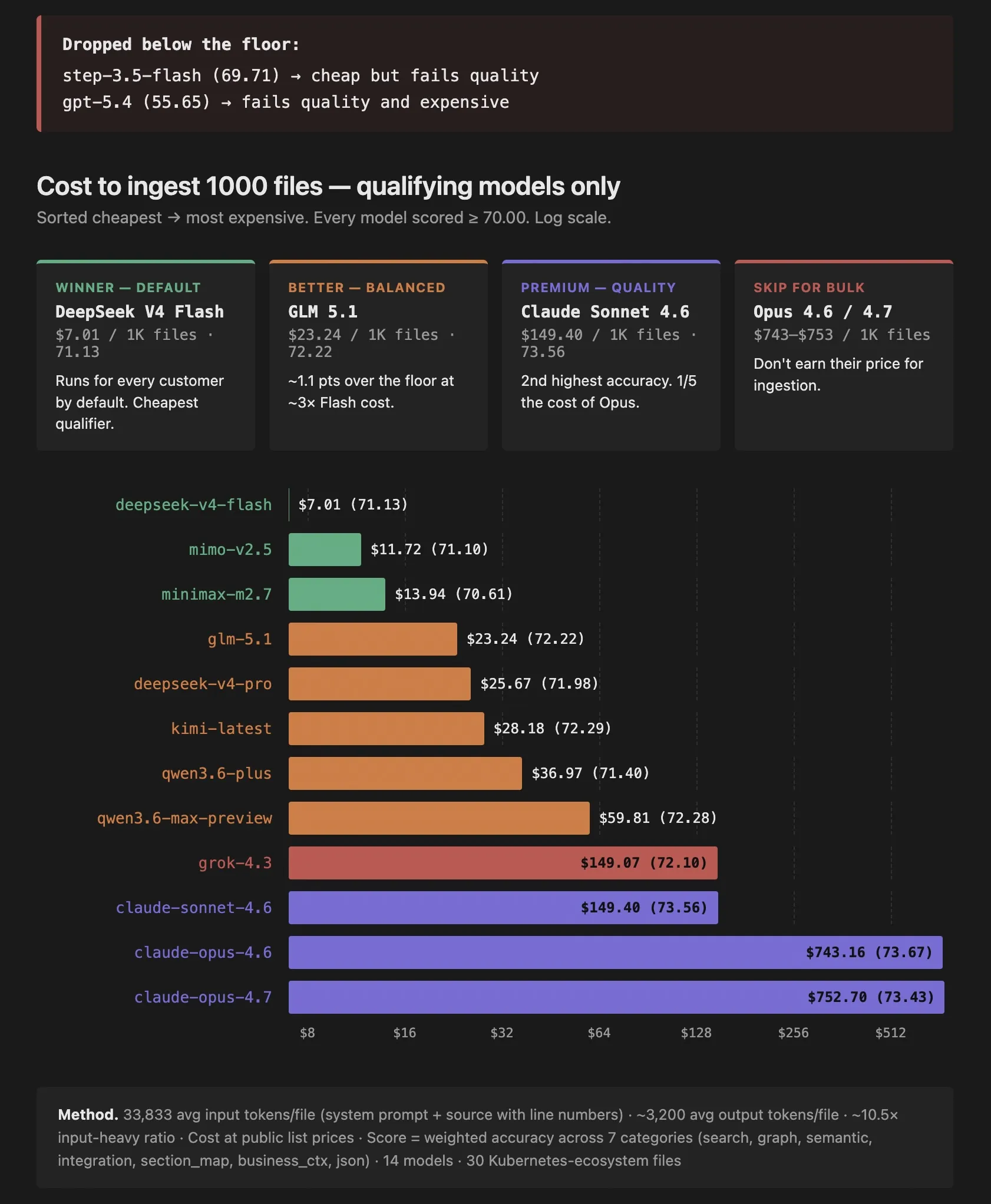
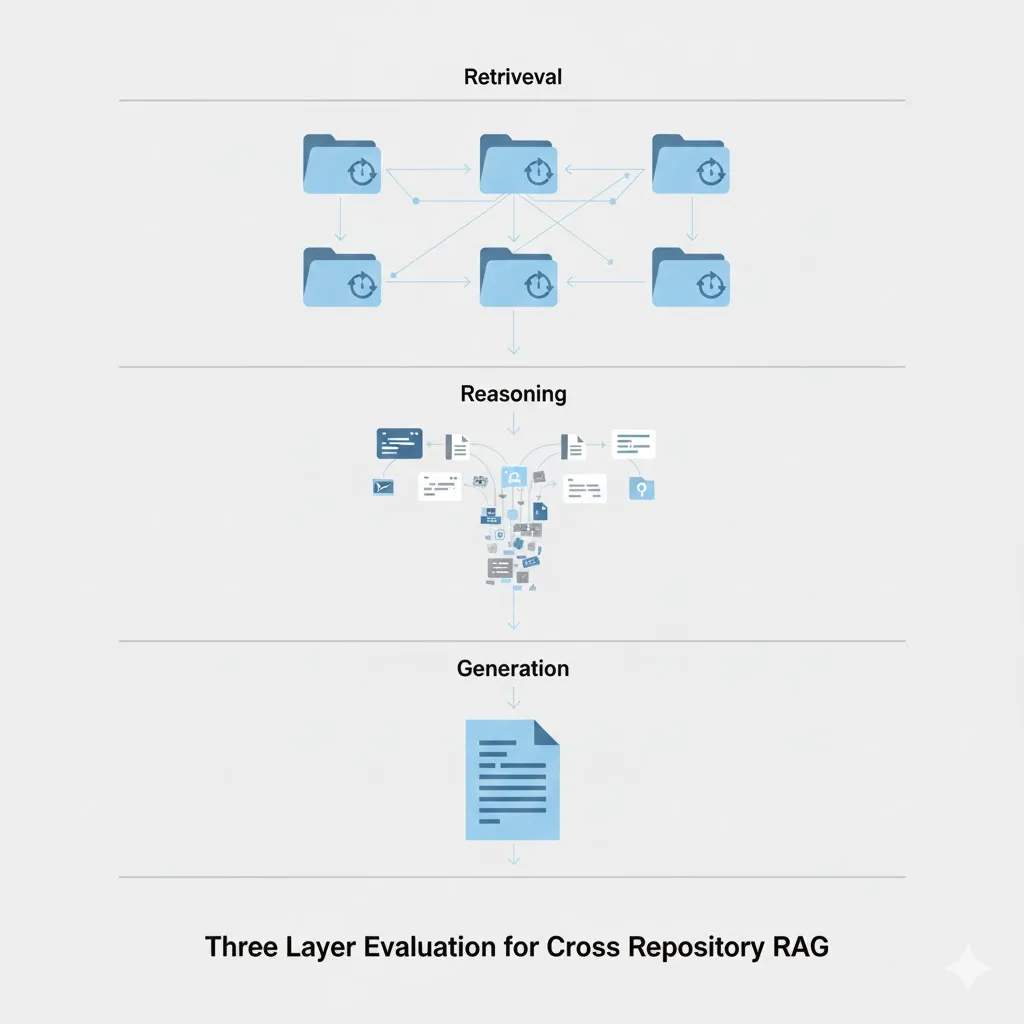
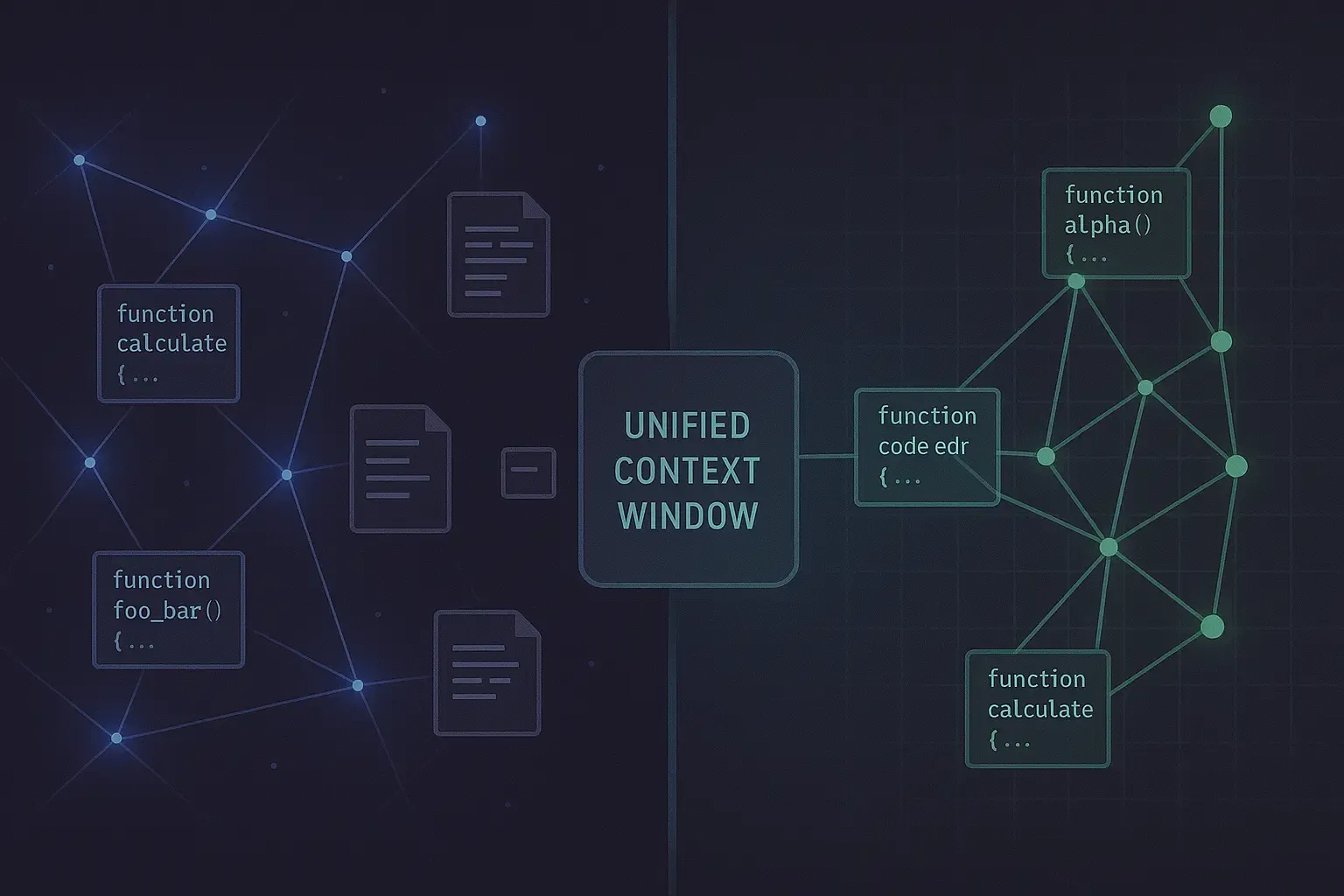
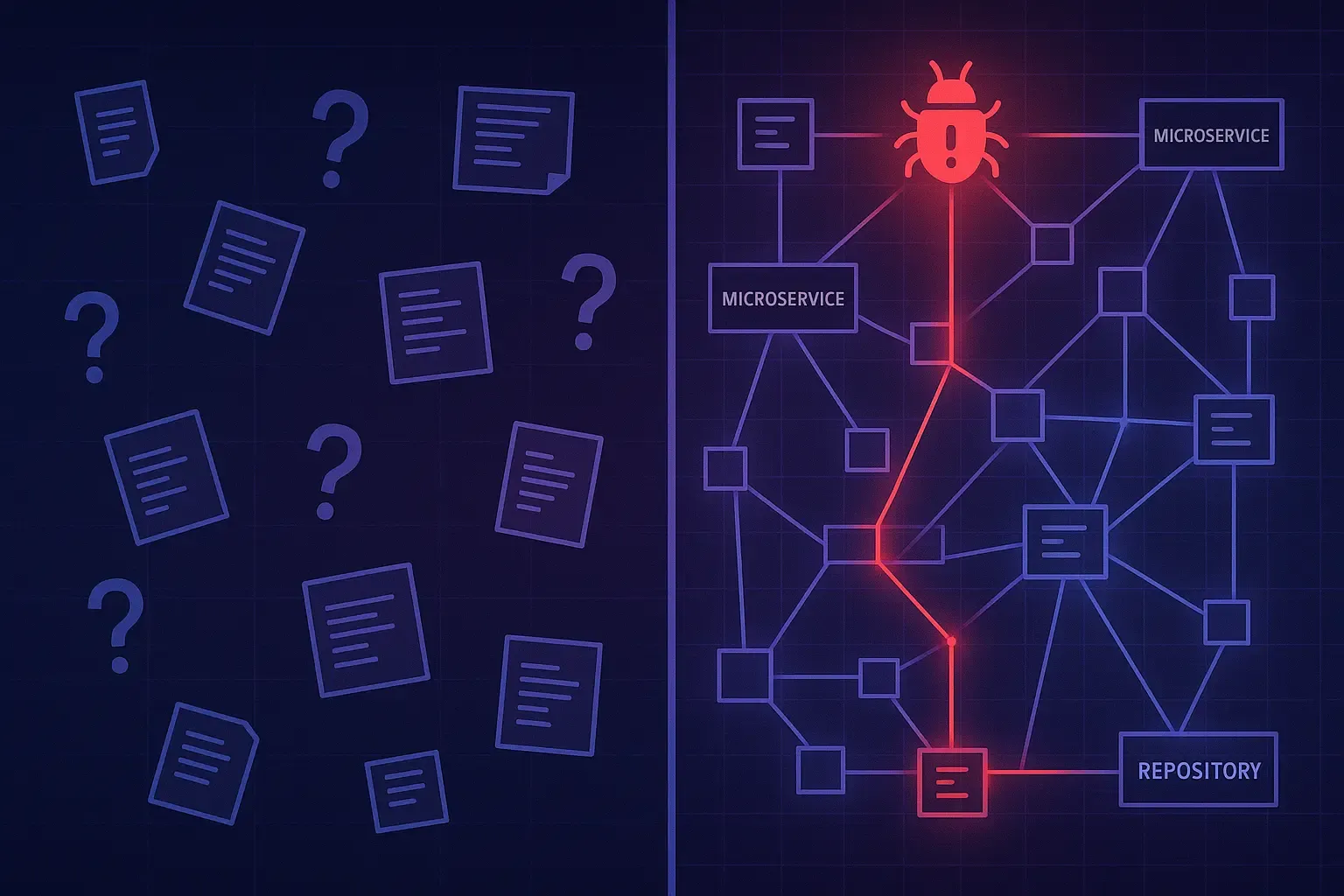
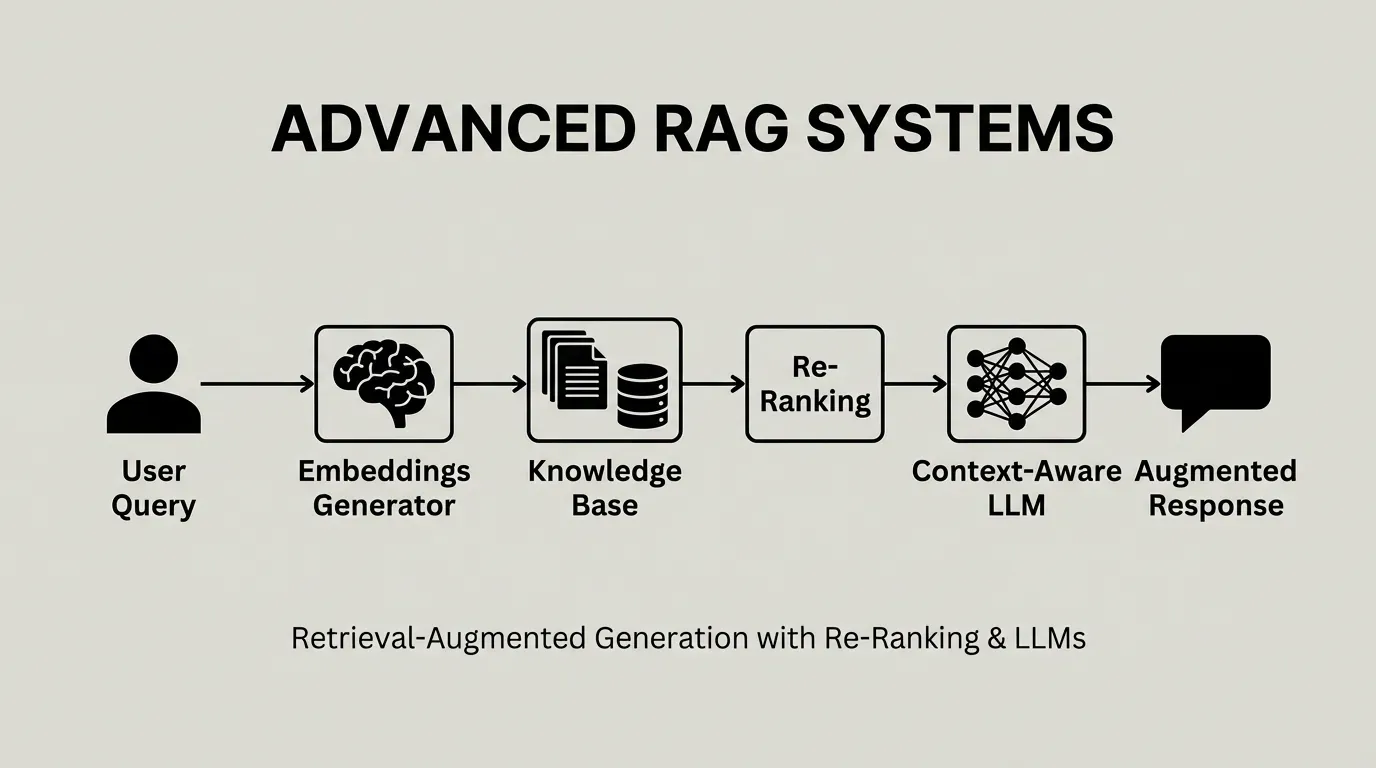
How to Handle GitHub Copilot's Token Costs Without Going Broke
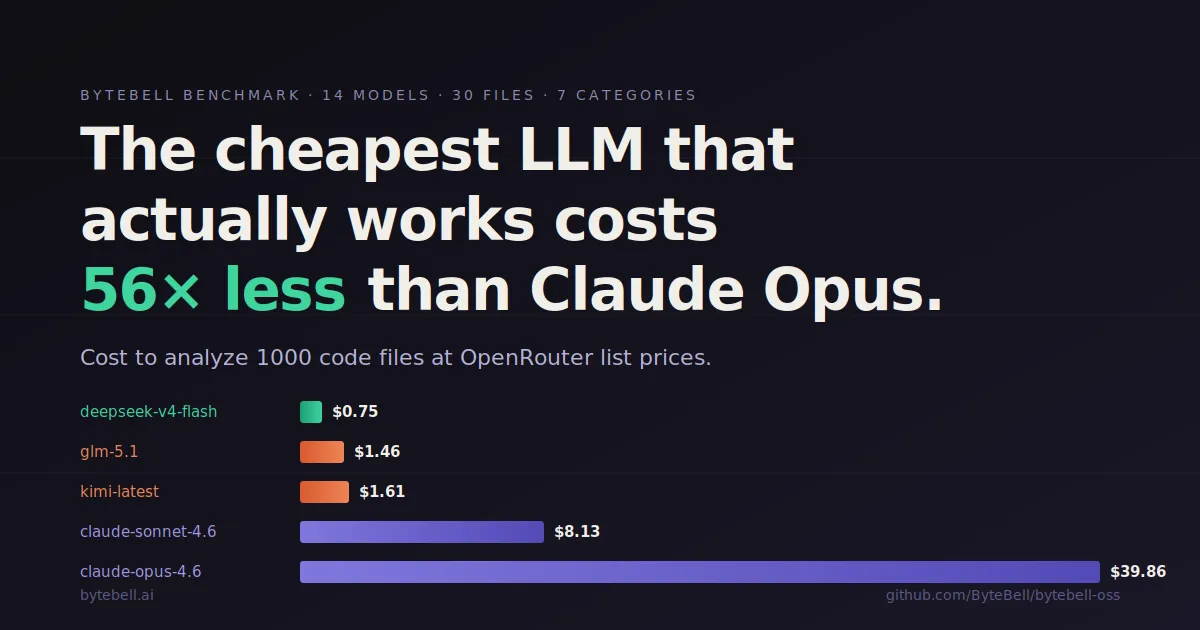
GitHub Copilot moved to per-token billing and one developer's bill jumped from about $29 to a projected $750. Switching tools won't save you, because the same shift is happening everywhere. Here's why your bill exploded in plain English, the practical levers that cut it today, and how verifiable specs attack the cost at its root.