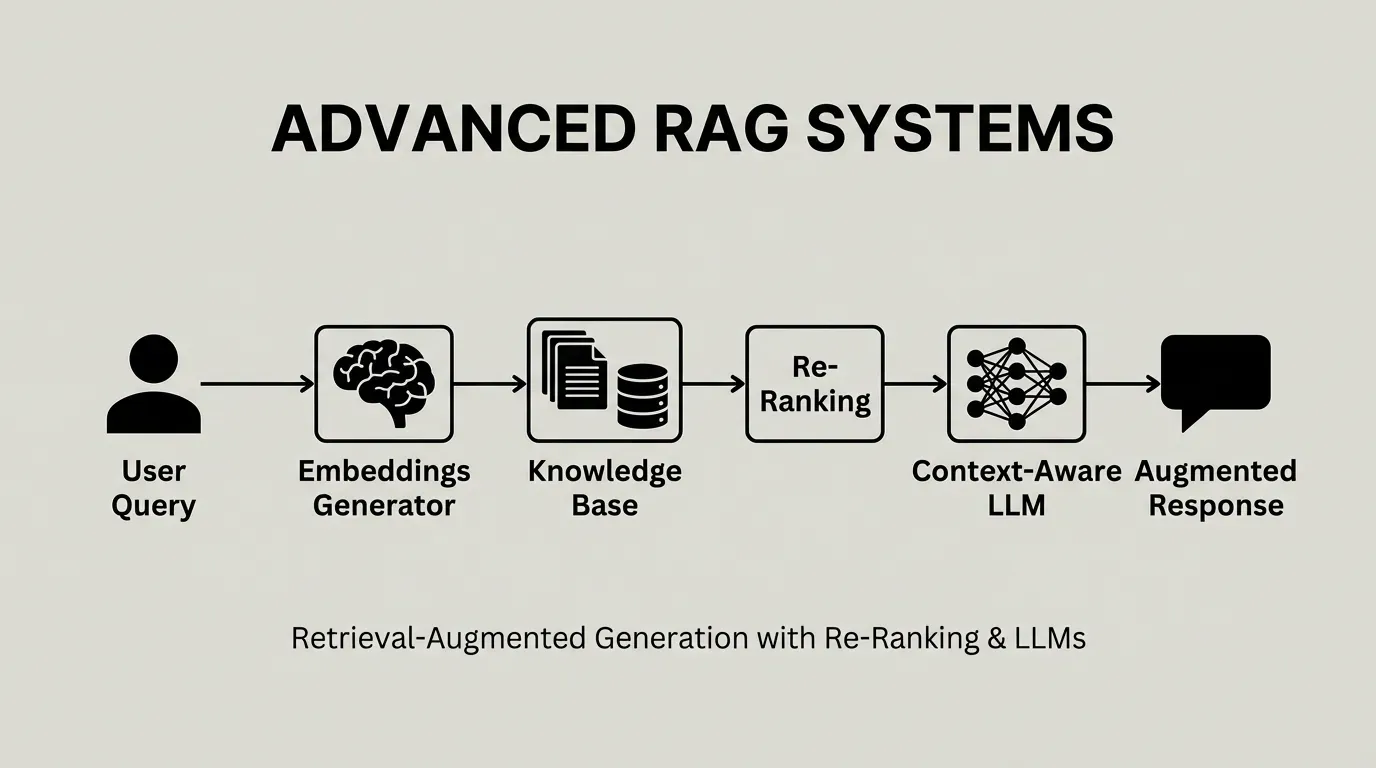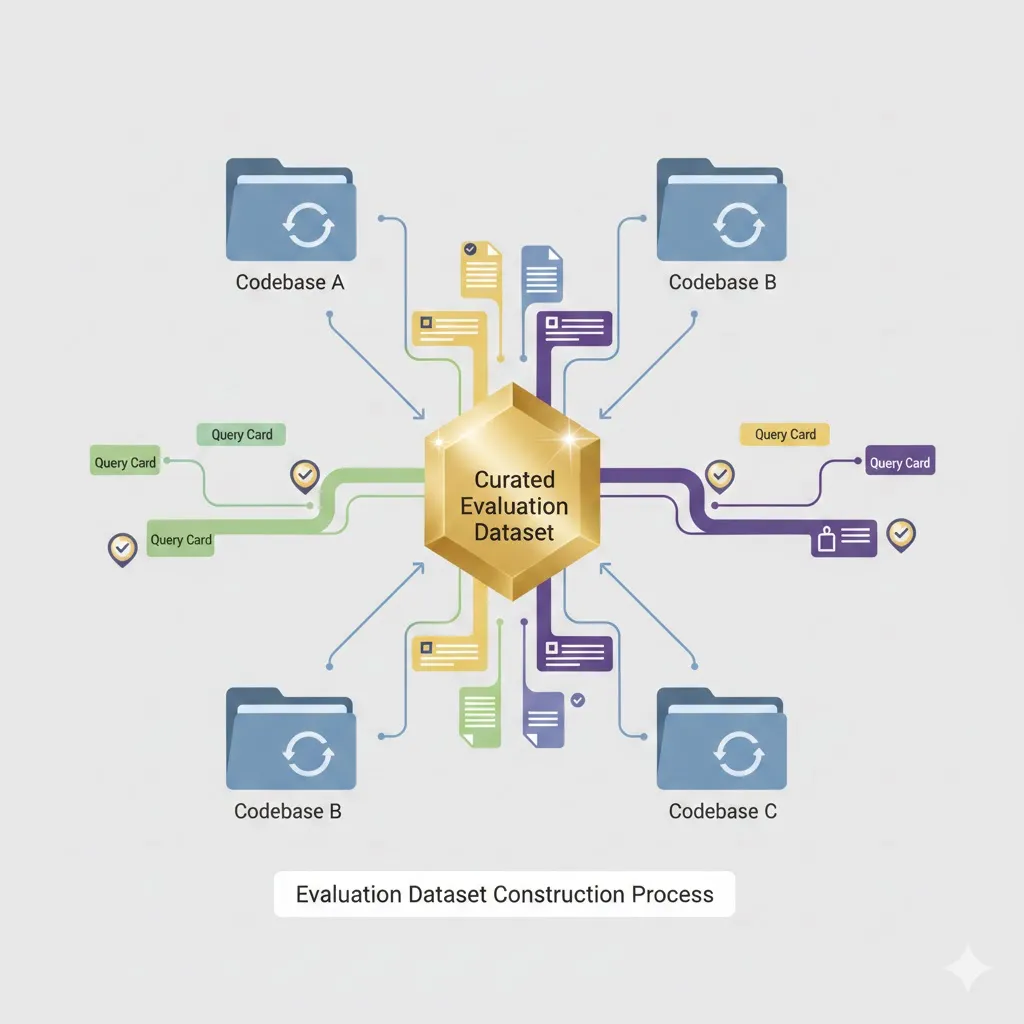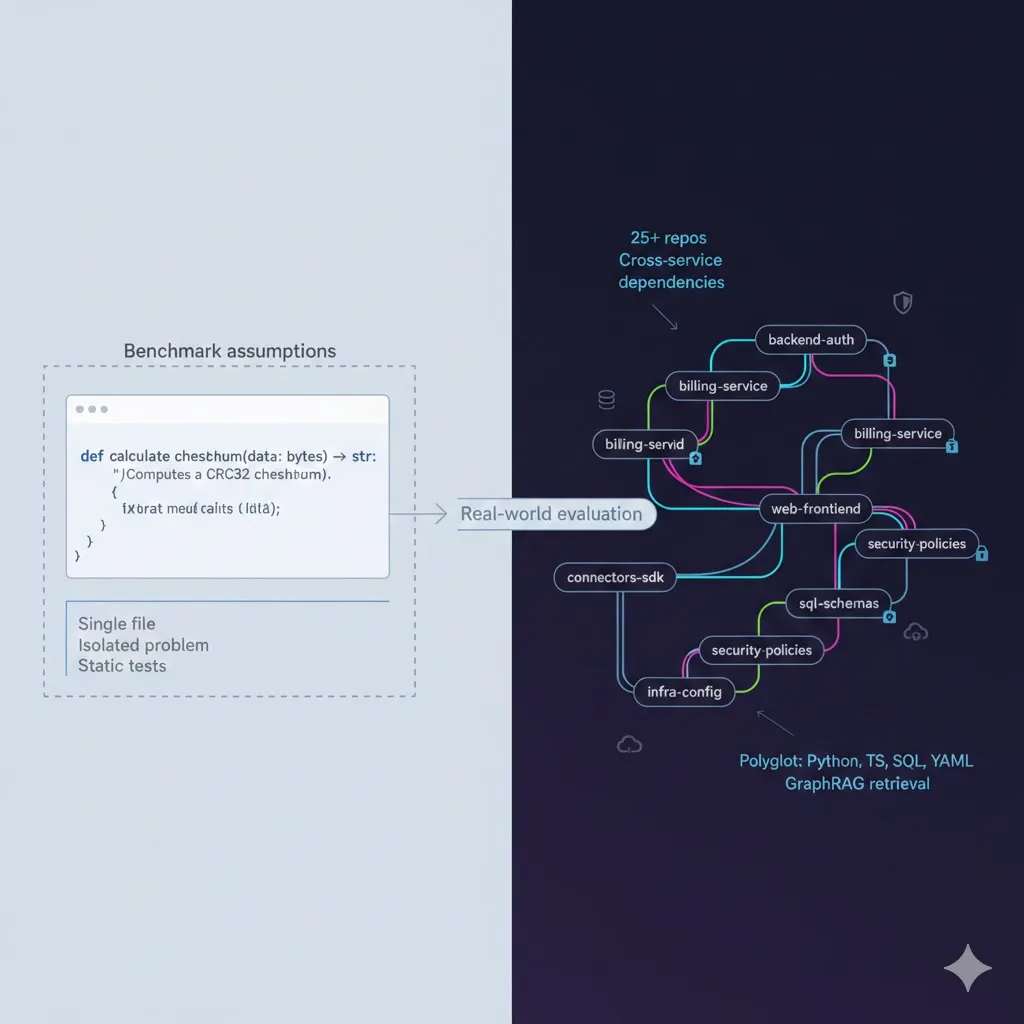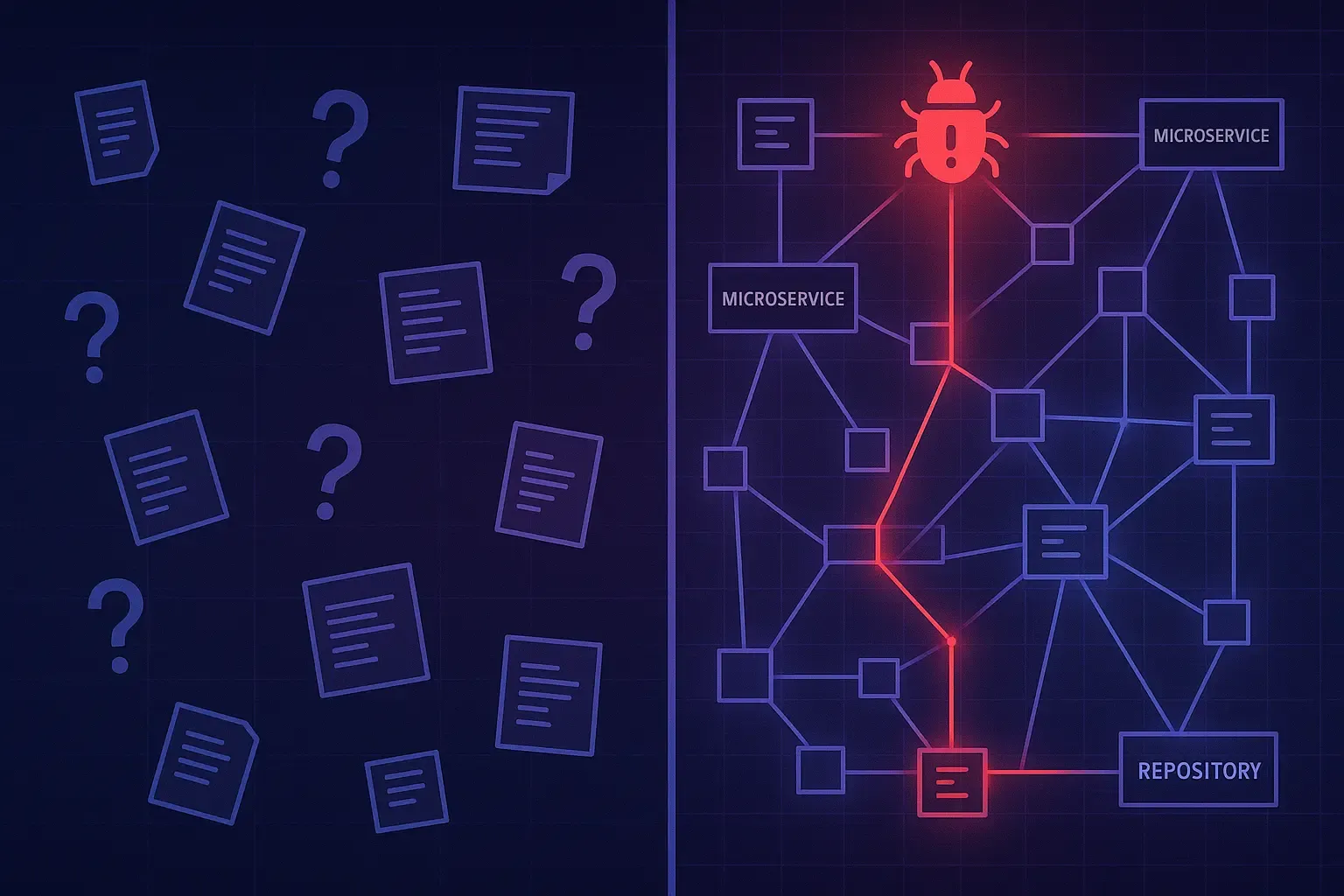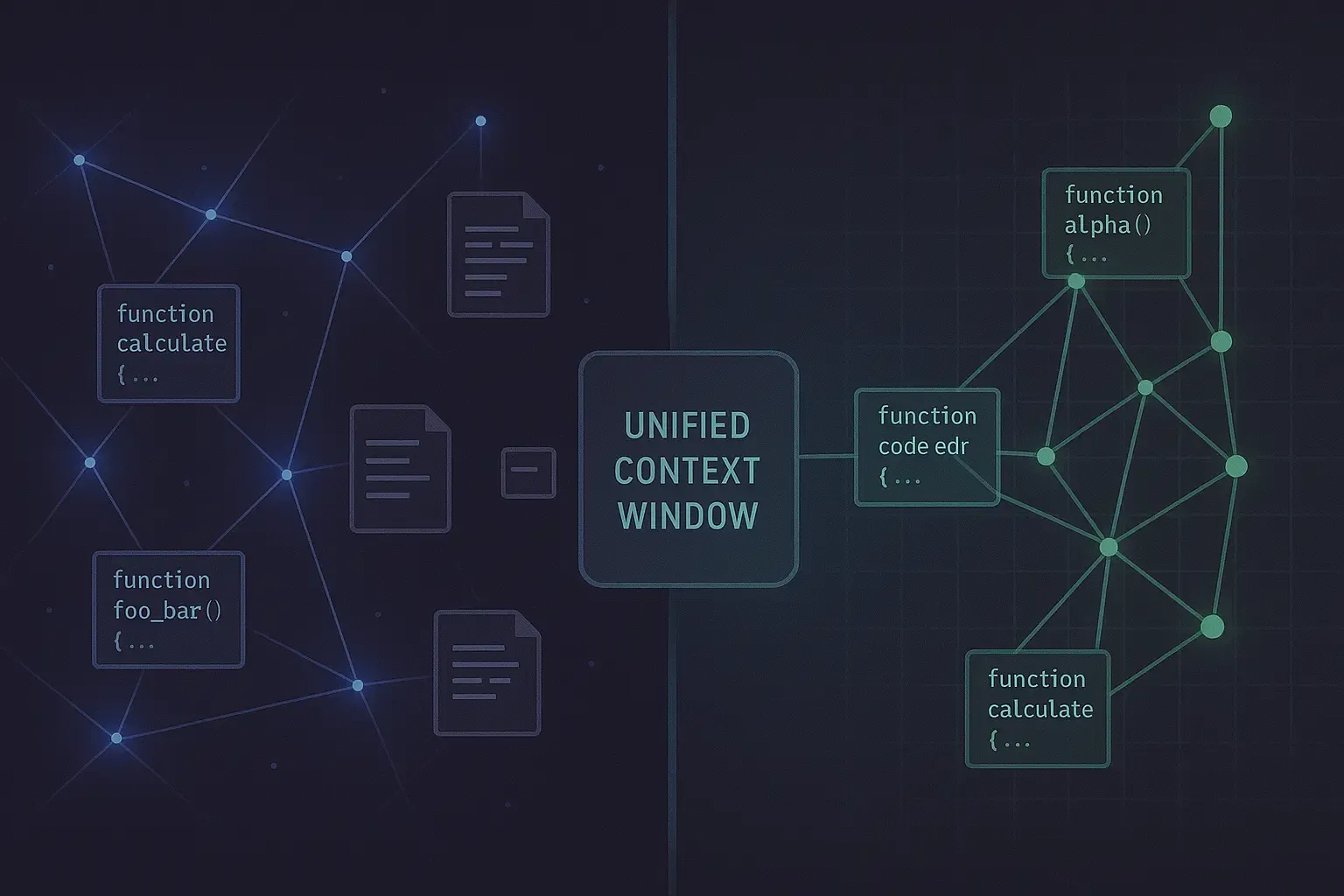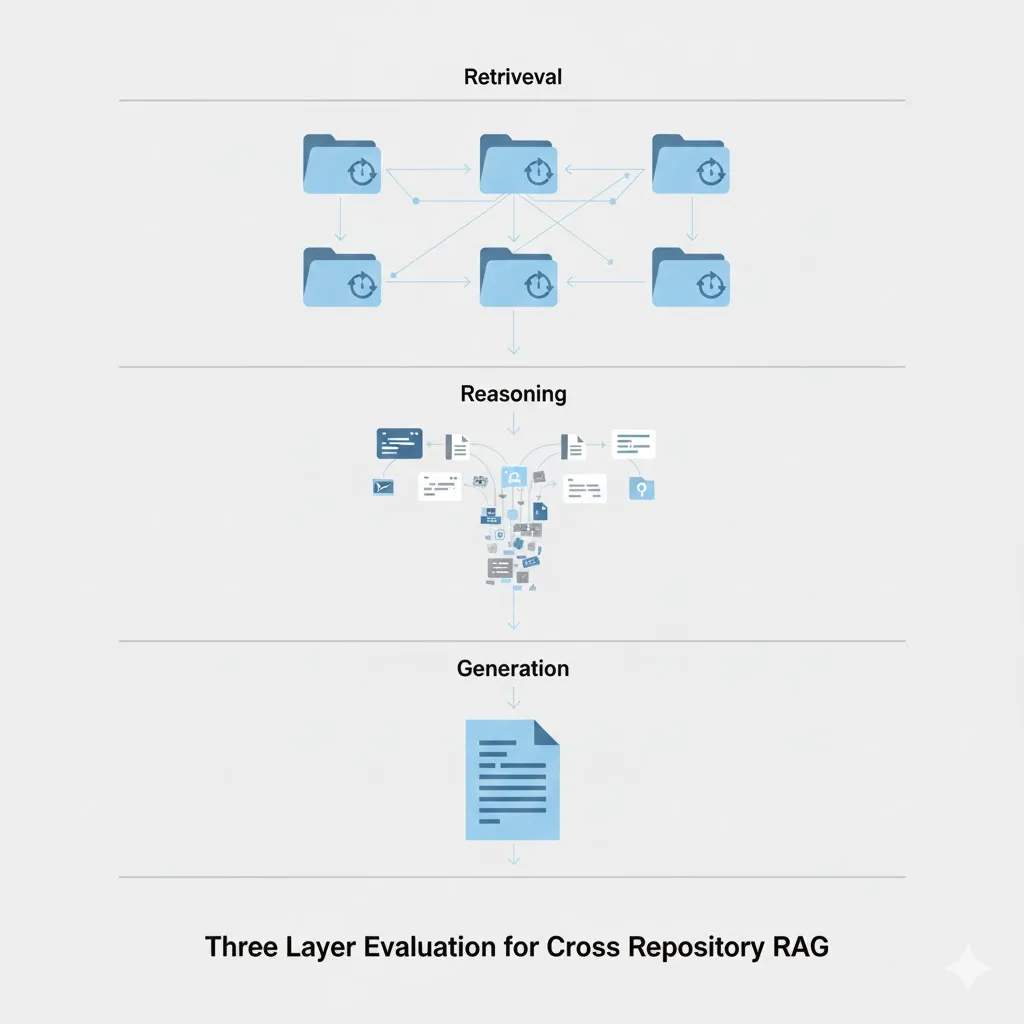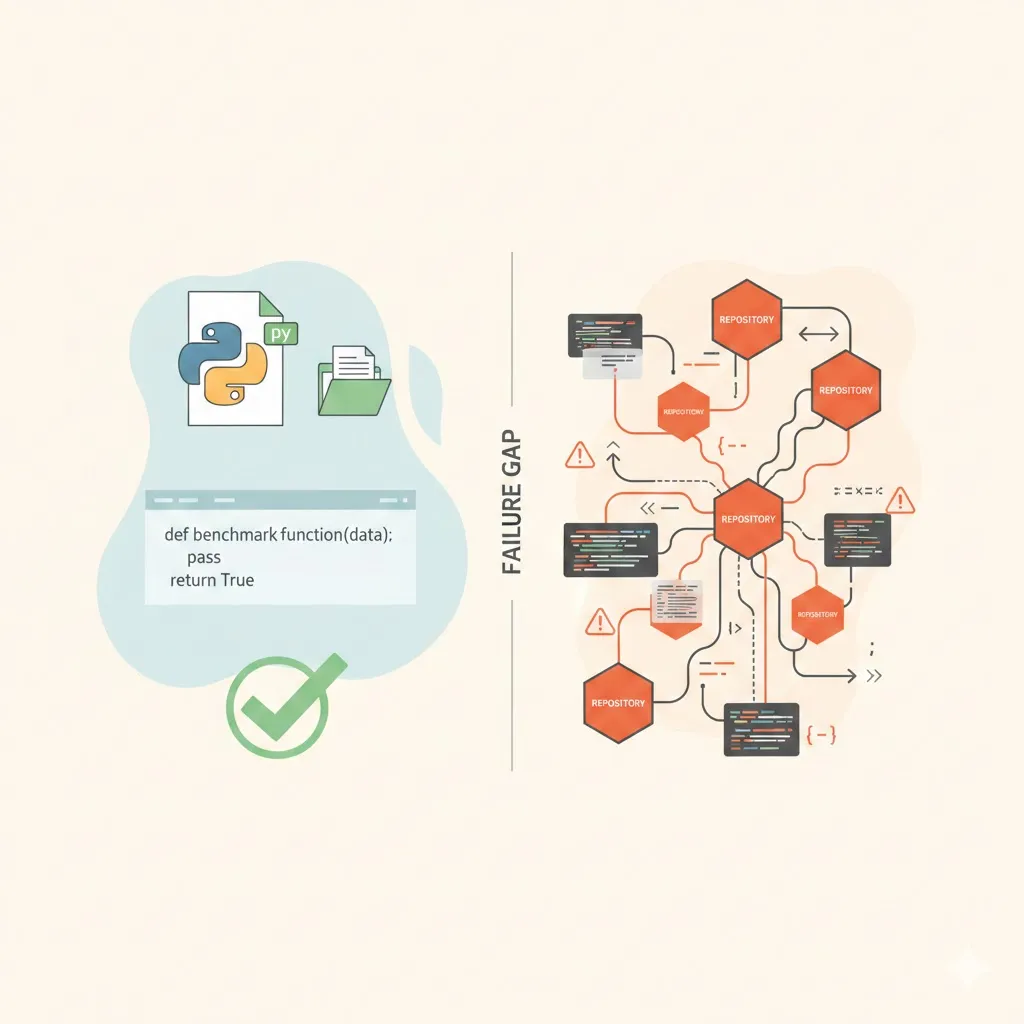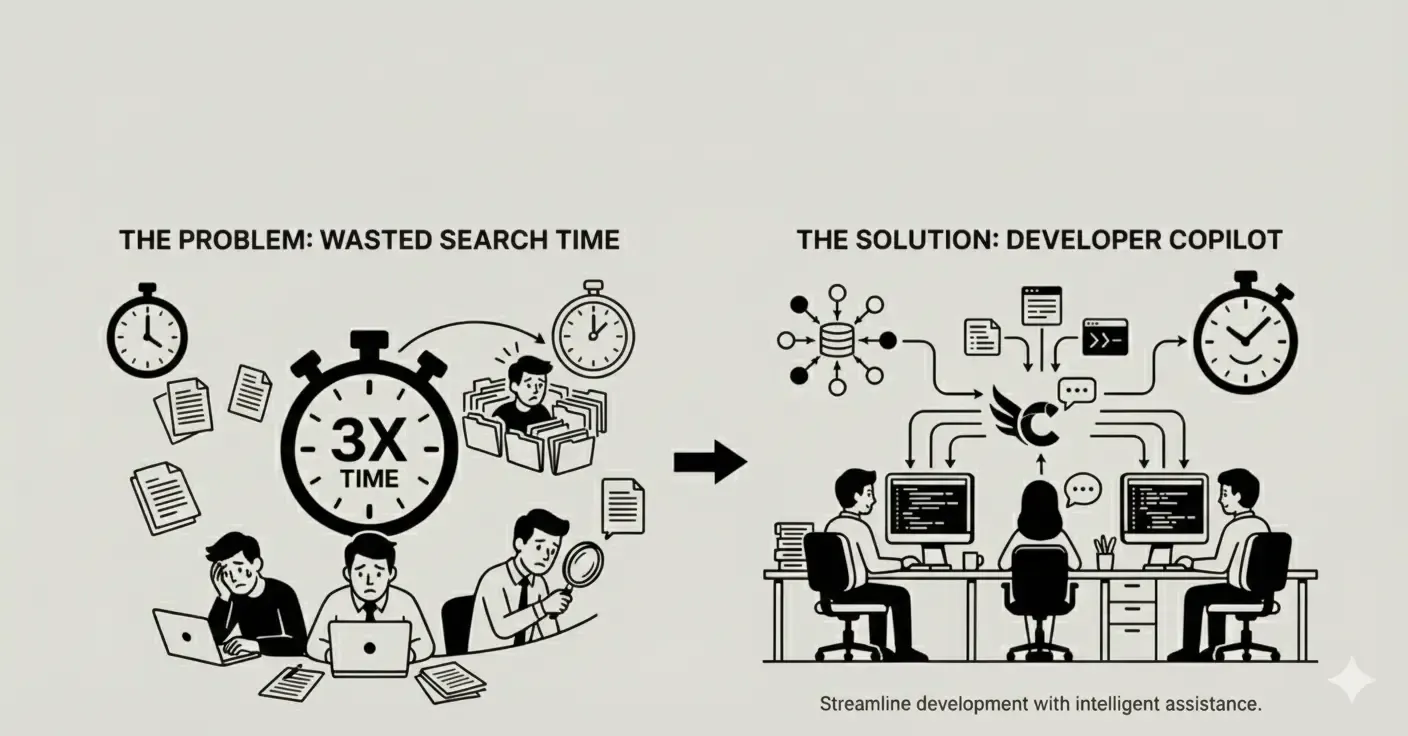
Why Your Team Spends 3X More Time Finding Answers Than Building—And How Context Copilots Fix It
Knowledge workers waste 3X more time searching for answers than creating. Learn how context copilots eliminate fragmented knowledge, information decay, and trust deficits to help engineering teams work faster with source-backed answers.