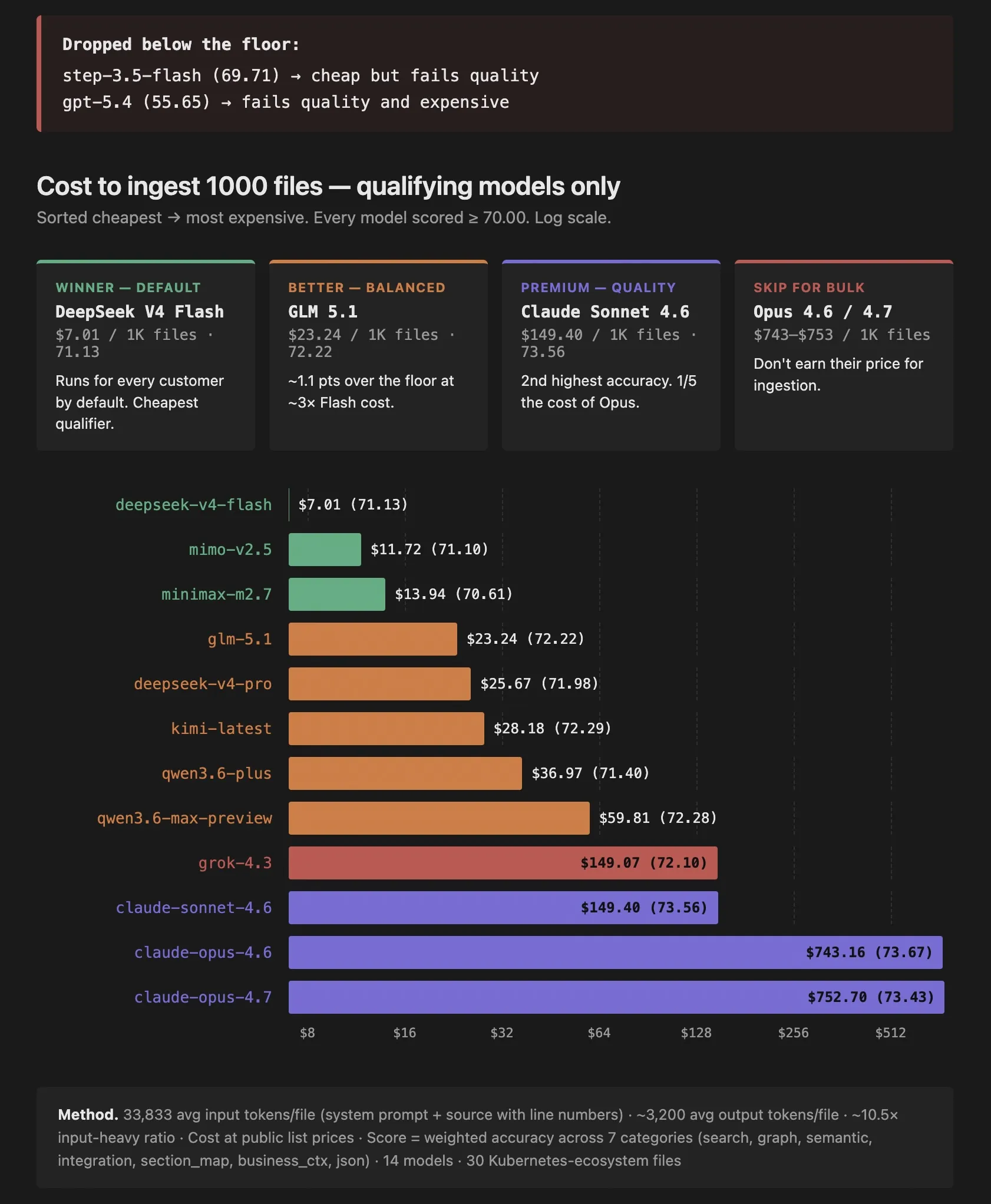
$13.30 to Compile 1,000 Files Into a Verifiable IR, Once
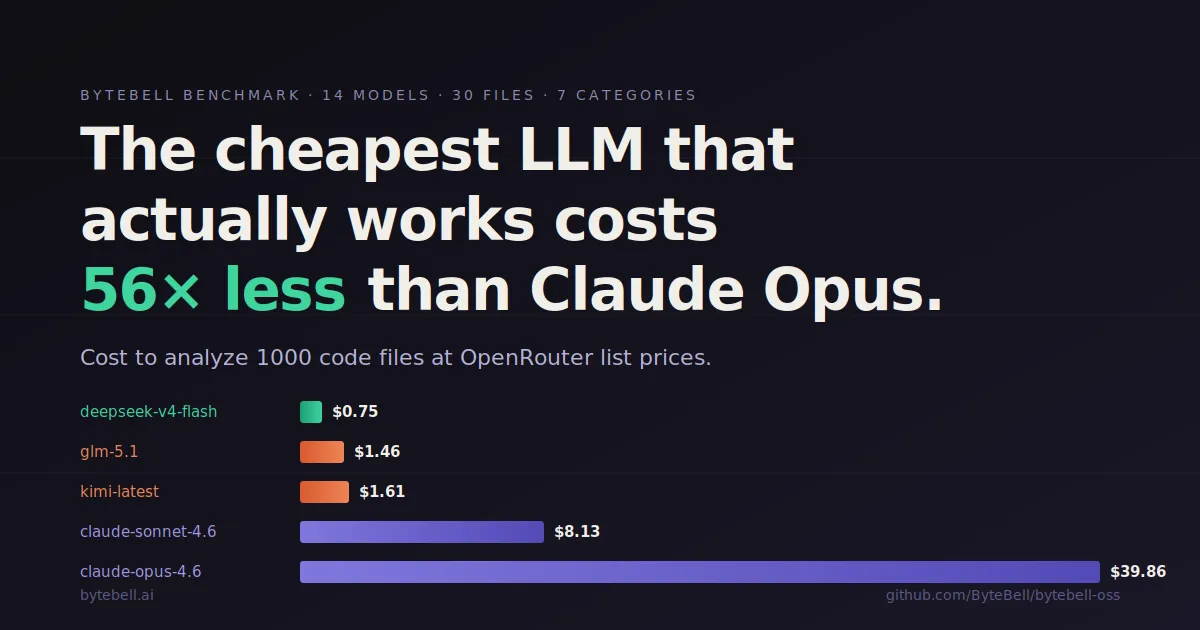
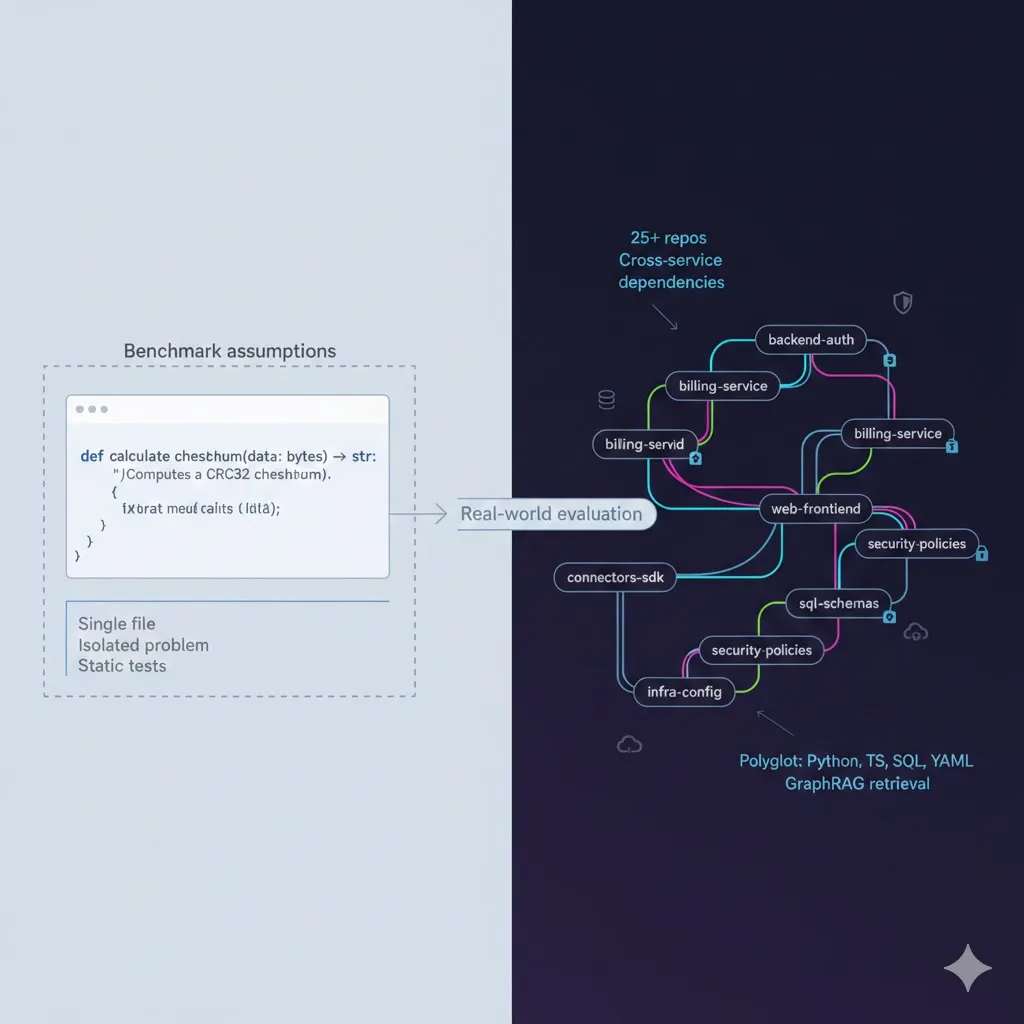
The objection to compiling a codebase into a verifiable IR is always cost. It sounds like Opus pricing across every file. It isn't. At open-source-model rates it runs about $13.30 per 1,000 files, you pay it once, and per-file diffing means you only ever re-pay for what changed. Here is the real economics of the verifiable context layer, and why the expensive thing is not building the IR but living without one.