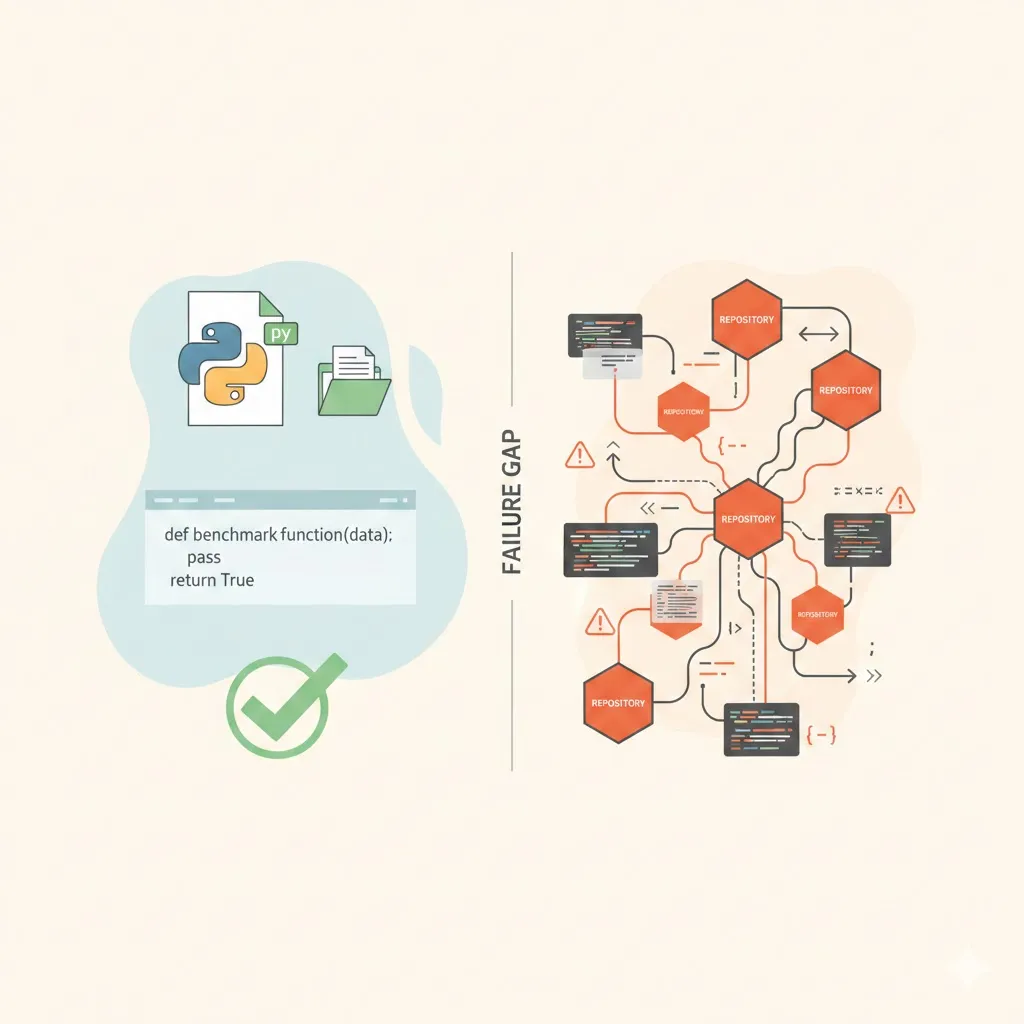
Why Standard Coding AI Benchmarks Fail for Cross-Repository Systems
Existing benchmarks like HumanEval, MBPP, and SWE-Bench assume single-file, isolated context and cannot evaluate GraphRAG systems that reason across tens of thousands of files, multiple repositories, and evolving services. This post explains the unique failure modes in cross-repository retrieval and what metrics actually matter.