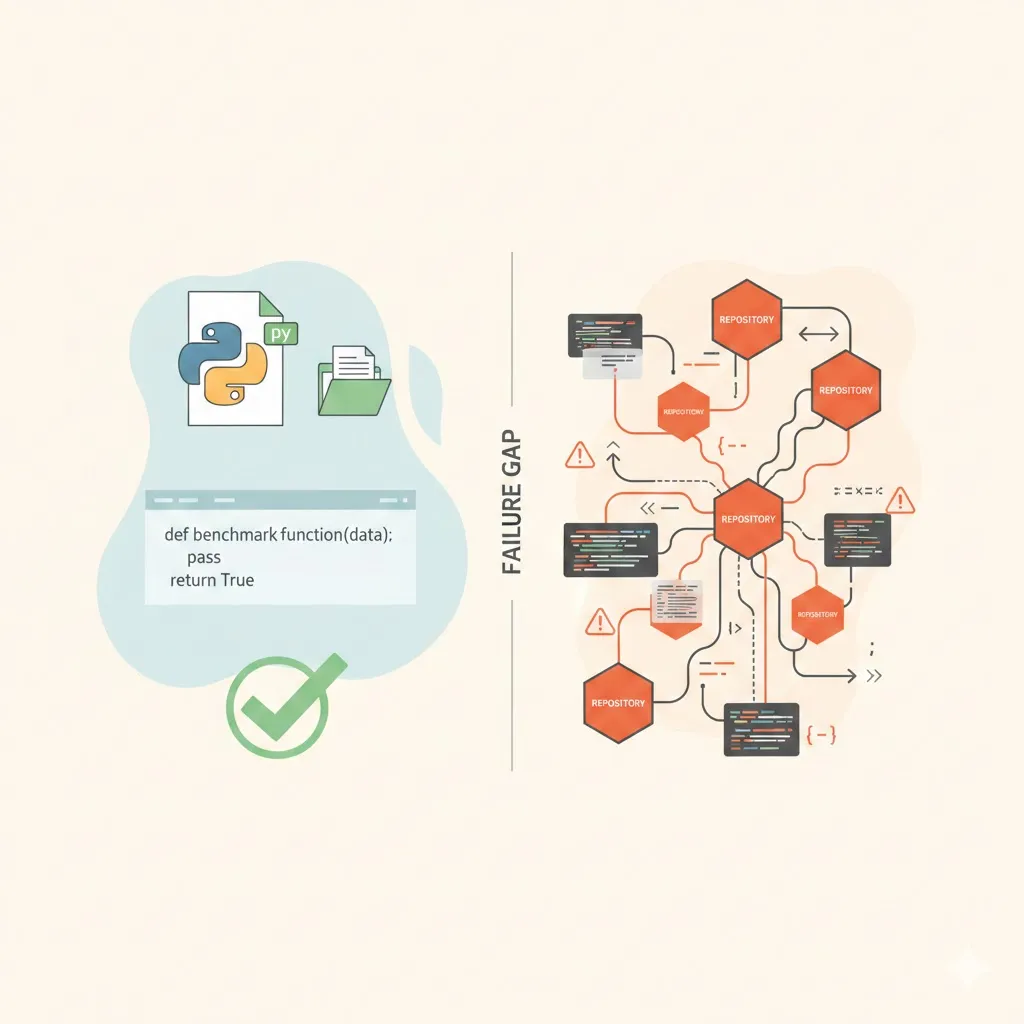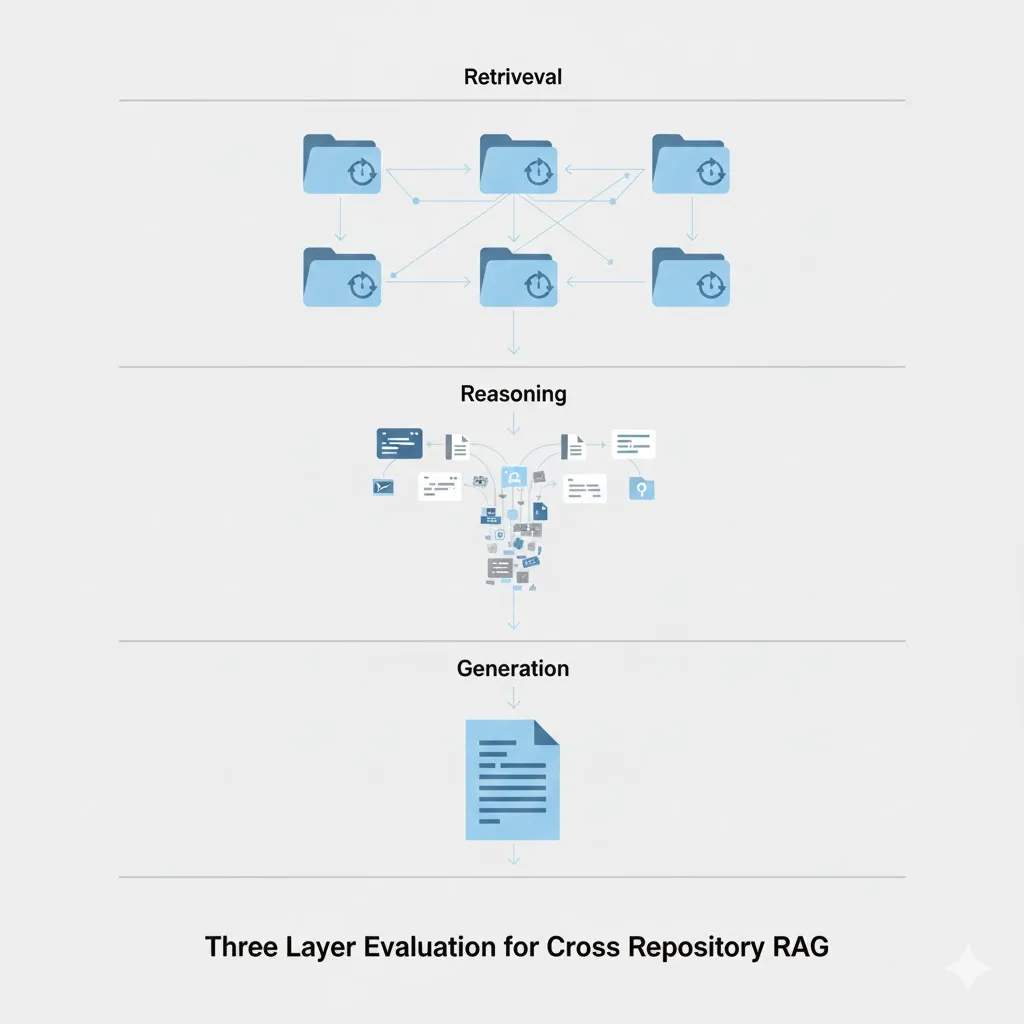
Designing a Three-Layer Evaluation Framework for Cross-Repository GraphRAG
A comprehensive evaluation architecture for GraphRAG systems operating across multiple repositories. This post introduces the retrieval → reasoning → generation framework with specific metrics, target thresholds, and implementation code for each layer.